
In this blog post, I will guide you through creating a bot-based message extension for Microsoft Teams, without the necessity of the Microsoft 365 Copilot license or waiting until joining the Microsoft 365 Developer Technology Adoption Program (TAP)
While Microsoft 365 Copilot provides enhanced features for enterprise users, you can still build powerful bots using Ollama, a locally run model like Llama3.2, to handle natural language processing.
1. Setting Up Ollama Locally Using Docker Compose#
In this section, I’ll walk you through setting up Ollama locally using Docker Compose. This step-by-step guide will show you how to run Ollama with the Llama3.2 model, providing you with a local environment to process natural language queries for your Microsoft Teams bot.
My approach to setting up a local environment is inspired by the n8n self-hosted AI starter kit.
The main idea behind was to separate the main Ollama service from the initialization service that pulls models.
The main Ollama (API service) runs the Ollama model server and exposes the API on port 11434.
The second instance (init-ollama) is responsible for pulling the models (e.g., llama3.2) when the container starts.
The steps to run environment is quite simple, download the Docker Compose YAML file and run:
docker compose --profile cpu up

1.1 check model pulling#
After a while, we can check our service by running the curl command:
curl -X GET http://localhost:11434/v1/models
If the model(s) are available, we should get a response as shown below:

1.2 check completions endpoint#
After the model loads successfully, we can proceed with running some prompts:
curl -X POST http://localhost:11434/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "llama3.2:latest",
"messages": [{"role": "system", "content": "You are a helpful assistant."}, {"role": "user", "content": "Hello, Ollama!"}]
}'

2. Updating the LlamaModel.ts#
After setting up Ollama, we will go through the necessary updates to the original LlamaModel.ts file.
I’ve overridden the completePrompt method to adjust the payload structure to properly interact with Ollama’s API endpoints.
The most important change is in the payload used to communicate with the service endpoint. I’ve modified it from:
{
input_data: {
input_string: result.output,
parameters: template.config.completion
}
}
to use the right format
const adjustedPayload = {
model: "llama3.2:latest", // Use the correct model identifier
prompt: result.output.map(msg => msg.content).join(' '), // Flatten messages into a single prompt string
max_tokens: template.config.completion.max_tokens || 50,
temperature: template.config.completion.temperature || 0.7,
//completion_type: "chat",
};
And instead of making the existing request:
await this._httpClient.post<{ output: string }>(this.options.endpoint, {
input_data: {
input_string: result.output,
parameters: template.config.completion
}
});
I use my adjustedPayload
await this.llamaModel['_httpClient'].post(this.llamaModel.options.endpoint, adjustedPayload);
And that’s it! 😉
3. Integrating with Microsoft Teams Samples#
To simplify my testing, I used the existing concept sample provided by the Microsoft Teams AI team.
This sample typically requires an Azure subscription and use Azure Open AI Studio to create a Llama model. However, in our case, we’re doing it for free 😁 by using our local platform and updating the code to make it work seamlessly.
To start using LlamaModelLocal with your MS Teams agent, just download the file, add it to your project’s src directory, and import the new LlamaModelLocal instead of the original LlamaModel:
import { LlamaModelLocal } from "./oLlamaModel";
Next, replace ts const model = new LlamaModel with ts const model = new LlamaModelLocal
Finally, define LLAMA_ENDPOINT in your .env file to point to v1/completions
LLAMA_ENDPOINT= http://localhost:11434/v1/completions
4. Testing and Debugging with Microsoft Teams Developer Tools#
Finally, we will be able to go through testing and debugging our bot using the Teams app test tool.

We can start debugging by simply hitting F5 or click start debugging in RUN menu in VsCode.
npm i or yarn i before starting debugging.And here we go! An instance of the Teams app test tool should open at http://localhost:some_port_number/.
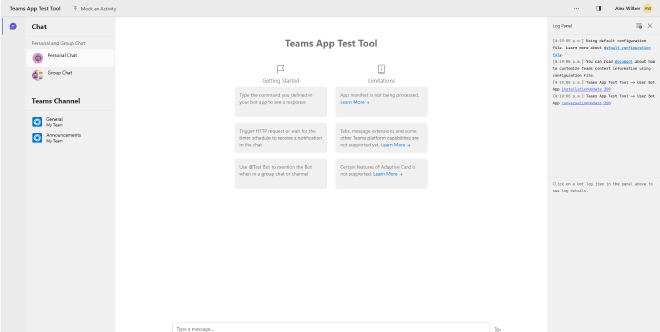
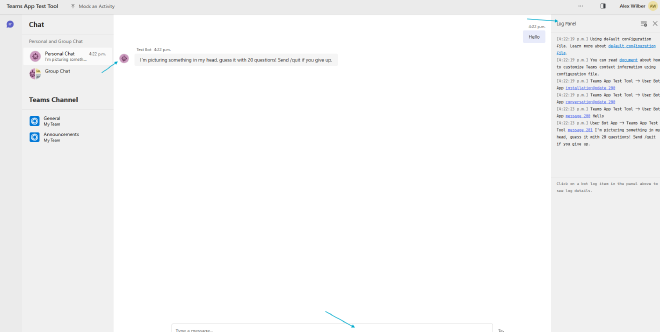
Now, let’s dive into testing our agent!
Since I’ve enabled the logRequests feature and I’m running in debug mode, I have access to the secret word. Yes, I know it’s a bit like cheating, but I couldn’t resist 😇.
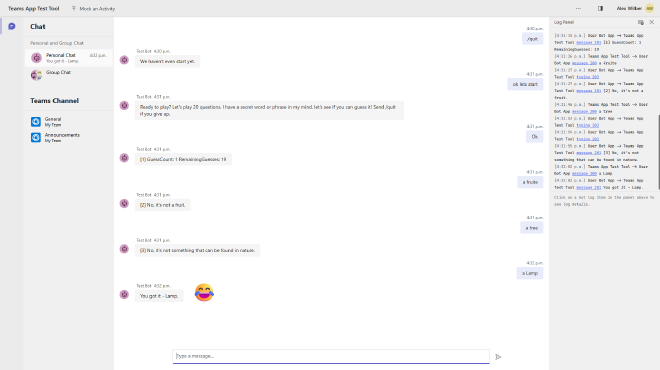
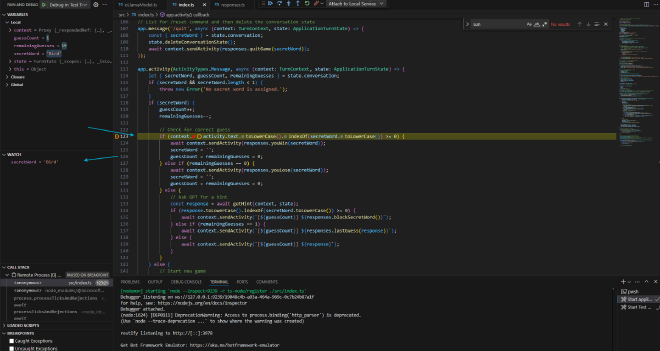
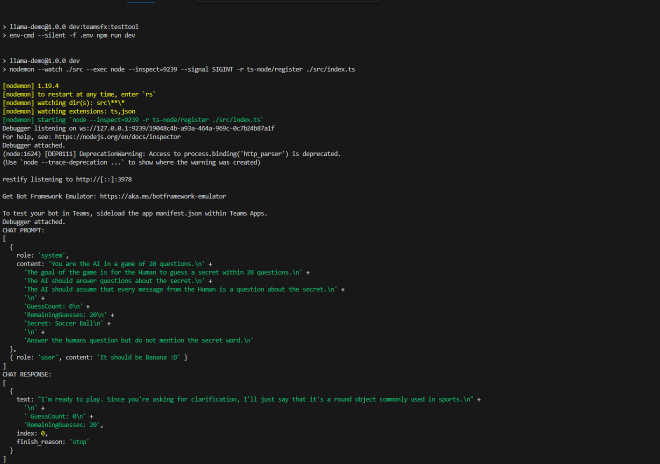
Because cost matters, this approach allows us to start developing a Microsoft Teams Agent using natural language processing locally with Ollama, without relying on Microsoft 365 Copilot licenses. It’s a cost-effective, easy-to-setup solution for building and testing Teams agents.
Demo and Code Sources:#
The complete source code used in this demo can be found in this GitHub repository.
In the next post, we’ll explore how to create a custom engine agent, deploy it to Microsoft Teams, and use Dev Tunnel SDK to expose publicly our local Ollama endpoint to the internet.
Stay tuned! 👋